
مدلهای بخشبندی در همهگیرشناسی
| علم شبکه | ||||
|---|---|---|---|---|
| انواع شبکه | ||||
| گراف | ||||
|
||||
| مدلها | ||||
|
||||
| ||||
|
|
||||

مدلهای بخشبندی مدلسازی ریاضی بیماری های واگیردار را ساده میکنند. یکی از پدیدههای مهم در علم شبکه نحوه پخش اطلاعات در آن است. اگر شبکه مورد نظر را یک جامعه انسانی و اطلاعات نشر شده بر روی آن را یک بیماری واگیردار در نظر بگیریم، به یک پدیده مهم میرسیم که در همهگیرشناسی نیز کاربرد دارد و آن نحوه پخش بیماری در شبکه است.
مدلهای پخش بیماری در شبکه[ویرایش]
در این متن قصد داریم، مدلهای پخش بیماری در شبکه را بررسی کنیم. ریاضیات مورد استفاده در این مدلها همان معادلات دیفرانسیل معمول است و نیاز به ریاضیات پیشرفتهتری نداریم. با این مدلها میتوانیم پیشبینیهای در مورد نحوه پخش بیماری در جامعه، درصد افرادی که با بیماری درگیر میشوند، احتمال شیوع گسترده بیماری و ... انجام بدهیم که در زمان شیوع بیماریهای واگیردار (مانند کووید ۱۹ یا همان کرونا) این پیشبینیها بسیار حیاتی و کلیدی میشوند.
در این مدلها، جمعیت مورد مطالعه به بخشهای محدودی با برچسبهایی مثل S , I، یا R (S مستعد بیماری، I آلوده یا بیمار، R مقاوم در برابر بیماری) تقسیمبندی میشوند. اعضای جامعه میتوانند از بخشی به بخش دیگر بروند وضعیتشان تغییر کند. ترتیب این برچسبها در نامگذاری این مدلها نشاندهندهٔ جریان تغییر وضعیت از بخشی به بخش دیگر است. به عنوان مثال، مدل SIR به معنای، مستعد، بیمار و مقاوم در برابر بیماری است.
مدل SI[ویرایش]
در این مدل افراد جامعه به دو دسته S (افراد سالمی که مستعد گرفتن بیماری هستند) و I (افرادی که در حال حاضر بیمار هستند) تقسیم میشوند. همچنین تعداد افراد کل شبکه برابر N میگیریم و در شبکه تولد و مرگی رخ نمیدهد و در نتیجه N ثابت است.
اگر k تعداد متوسط همسایههای یک راس در شبکه، نرخ تغییرات تعداد بیمارها (با استفاده از مدل میانگین در مکانیک آماری) به صورت زیر است که در آن بتا احتمال انتقال بیماری به او (در بازه زمان dt) و PI درصد افراد بیمار در شبکه است. (برای درک نحوه به دست آمدن این رابطه میتوانید به کتاب علم شبکه اثر باراباسی-آلبرت مراجعه کنید):

برای راحتی کار I/N را برابر i تعریف میکنیم و به همین ترتیب s را برابر S/N تعریف میکنیم. از آنجایی که N باید ثابت باشد آهنگ تغییرات S برابر منفی آهنگ تغییرات I است و در نتیجه دستگاه معادلات به شکل زیر در میآیند:

از حل این دستگاه معادلات میتوانیم به رابطه زیر برای i بر حسب زمان برسیم:




این رابطه بیان میکند که در ابتدا که i کوچک است، تعداد افراد بیماری با سرعت کم افزایش پیدا میکند اما بعد شتاب گرفته و بعد از مدتی با سرعت بیشتری تعداد افراد بیمار افزایش پیدا میکند و در نهایت نیز چون تعداد افراد سالم کاهش پیدا کرده است، سرعت افزایش تعداد بیماران نیز کاهش پیدا میکند تا در نهایت همه افراد بیمار شده و i برابر یک میشود. در شبیهسازی و نمودار زیر میتوانید این مدل را در یک شبکه مشاهده کنید.
مدل SIS[ویرایش]
در این مدل که نسبت به مدل SI واقعیتر است، فرض میکنیم که هر فرد بیمار با احتمال میو (در بازه زمانی dt)، بیماریاش برطرف میشود و سالم میشود.

بدین ترتیب دستگاه معادلاتمان این بار به صورت زیر در میآیند:

در این آهنگ تغییرات تعداد بیماران در دو نقطه صفر میشود. یک زمانی که i=0 باشد و بار دیگر زمانی که i برابر باشد. البته اگر باشد، دیگر i به محل دوم نمیرسد، و بعد از مدتی تعداد بیماران صفر میشود و این یعنی دو حالت داریم:


- اگر باشد، تعداد بیماران اگر از یک تعداد اولیه شروع شود، افزایش پیدا میکند و i به میل میکند. نمودار این حالت را میتوانید در زیر ببینید.
- اگر باشد، تعداد بیماران اگر از یک تعداد اولیه شروع بشود، به مرور کم میشود و در جایی تعداد بیماران به صفر میرسد و شیوع بیماری تمام میشود.
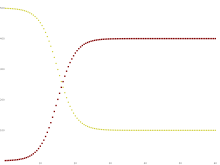
نمودار تغییرات تعداد افراد سالم (رنگ زرد) و افراد بیمار (رنگ قرمز) در مدل SIS در حالت او


مدل SIR[ویرایش]
این مدل که که میتوان گفت از دو مدل قبلی واقعیتر است، فرض بر این است که فرد بعد از گرفتن بیماری یا بهبود پیدا میکند و دارای پادتن بیماری میشود یا متاسفانه فوت پیدا میکند، که در هر دو صورت فرد در مقابل بیماری مقاوم میشود. این دسته افراد مقاوم در برابر بیماری را با R نشان میدهیم. باز هم فرض بر این است که N شبکه تغییر نمیکند و در نتیجه مجموع R,S,I برابر N است. همچنین R/N را به صورت r تعریف میکنیم.
در این مدل هر فرد بیمار با احتمال میو (در بازه زمانی dt)، به دسته R میپیوندد (یا میمیرد یا بهبود پیدا کرده و دارای پادتن بیماری میشود) و در مقابل بیماری مقاوم میشود.
بدین ترتیب دستگاه معادلات در این مدل به شکل زیر درمیآیند:

این معادلات را میتوان به صورت زیر نیز بازنویسی کرد:


در این مدل نیز دو حالت داریم:
- اگر ، تعداد بیماران همواره کاهشی است و بالاخره صفر میشود و شیوع بیماری تمام میشود.
- اگر تعداد بیماران تا نقطه افزایشی است و بعد از آن کاهشی میشود و به صفر میرسد. به عبارت دیگر تعداد بیماران دارای یک قله میشود. شاید اگر زمان شیوع بیماری کرونا را به یاد داشته باشید، این قلهها در تعداد بیماران در نمودارهایی که روزانه اخبار منتشر میکرد، به یاد داشته باشید. نمودار این حالت را میتوانید در روبهرو مشاهده کنید.
در این مدل کمیتی به صورت تعریف میکنند. این کمیت به نوعی بیانگر تعداد افرادی است که یک فرد در بازه مبتلا بودن خود به بیماری، میتواند بیمار کند. اگر بزرگتر از یک باشد، بیماری شیوع پیدا میکند ولی اگر کوچکتر از یک باشد، بیماری سریعا کاهش پیدا میکند و اصلا شیوع چندانی پیدا نمیکند. برای مثال در شیوع بیماری کرونا، سویه سویه امیکرون سارس کووید ۲ آن دارای بزرگتری نسبت به سایر سویهها بود و بیشتر از سایر سویهها بود و در نتیجه بیشتر از آنها نیز شیوع پیدا کرد ولی خوشبختانه نسبت به سویه دلتای سارس کووید ۲، دارای کشندگی کمتری بود و در نتیجه با شیوع سویه امیکرون تعداد کشتههای بیماری کاهش پیدا کرد.


مدلسازی واکیسناسیون[ویرایش]
تعداد بیماران چگونه در شبکه تغییر پیدا میکند؟[ویرایش]
در هر سه مدل فوق همانگونه که مشاهده کردیم در زمانی که i کوچک است، این کمیت به صورت نمایی رشد میکند:

اینکه تعداد بیمار در ابتدا کاهشی باشد یا افزایشی به کمیت داخل تابع نمایی بستگی دارد. برای مدل SI که همواره این کمیت مثبت است و همانگونه که مشاده کردیم در این مدل تعداد بیماران همواره در حال افزایش است تا کل شبکه بیمار شود. اما در دو مدل دیگر، همانگونه که قبلتر نیز اشاره کردیم، افزایش یا کاهش بیماران به کمیت بستگی دارد. اگر این کمیت بزرگتر از یک باشد، تعداد بیماران افزایش و اگر کوچکتر از یک باشد، تعداد بیماران کاهش پیدا میکند.
چه تعداد از افراد را واکسینه کنیم تا شیوع بیماری به اتمام برسد؟[ویرایش]
قرض کنید درصدی از افراد سالم را واکسینه کنیم و با در نظر گرفتن درصد عملکرد درست واکسن، g درصد از افراد سالم واکسینه شوند و در نتیجه به تعداد از افراد سالم میتوانند دچار بیماری بشوند، در نتیجه رابطه تغییر تعداد بیماران به صورت زیر درمیآید:





تاثیر ساختار بر شیوع بیماری[ویرایش]
در مدلهای فوق فرض کردیم که شبکه ما تصادفی و از مدل اردوش-رنیی پیروی میکند و در نتیجه درجهٔ راسها تفاوت چشمگیری باهم ندارند و تقریبا باهم برابراند. اما در واقع با توجه به بررسیهایی که انجام شده است، نشان داده شده است که شبکه جوامع انسانی به شبکه بیمقیاس مشابهتر است. و همانطور که میدانیم در این شبکهها درجه راسها به صورت فاحشی باهم متفاوت هستند و در نتیجه افراد دارای همسایههای با تعداد متفاوتی هستند. برای همین است که دیگر مدلسازیهای پیشین برای شبکههای واقعی انسانی کار نمیکنند. در این شبکهها نشان داده میشود که در مدل SIS کمیتی که در رشد یا کاهش تعداد بیماران تاثیرگذار است، به صورت زیر است[۱]:



البته نکته امیدوارکننده اینجا است که در این شبکهها تاثیر شاهراسها (به انگلیسی HUB) در شبکه بالاست و با کنترل هدفمند این شاهراسها را (که دارای تعداد همسایه بسیار زیادی هستند)، میتوان جلوی شیوع بیماری را گرفت. گرچه در شبکههای واقعی به دست آوردن و مدل کردن توپولوژی شبکه و کشف این شاهراسها بسیار سخت و بلکه تقریبا ناممکن است.
بنابراین به طور کلی با توجه به پارادوکس دوستی، اگر از هر فرد دوستهای او را بپرسیم و برویم آنها را واکسینه کنیم (با توجه به اینکه آن دوستها به صورت میانگین دارای همسایههای بیشتری هستند)، به صورت موثری میتوانیم جلوی شیوع بیماری را بگیریم.
مشکلات این مدلها[ویرایش]
مدلهای فوق دارای چند مشکل عمدهاند که باعث میشود با شبکههای واقعی فاصله داشته باشند:
- همانگونه گفته شد این مدلها برای شبکه تصادفی به دست آمده است، در حالی که شبکههای واقعی بیشتر شبیه شبکههای بیمقیاس هستند.
- در این مدلها شبکهها را بدون تحول در تعداد راسهای آن در نظر گرفتیم و تاثیر تولد و مرگ افراد را در شبکه در نظر نگرفتیم.
- این شبکهها بدون پارامتر زمان بودند. یعنی تاثیر اینکه یک راس به چه ترتیب زمانی راسهای دیگر را میبیند را در نظر نگرفتیم و فرض کردیم که یک راس همواره با همسایههای خود در ارتباط است که این فرض در شبکههای واقعی وجود ندارد.
- هر فرد در شبکه با مدت زمان یکسانی در ارتباط با همسایههایش نیست و در نتیجه یالهای بین راسها یکسان نیستند و به نوعی گراف وزندار است که ما این مورد را نیز در شبکهمان در نظر نگرفتیم.
جستارهای وابسته[ویرایش]
- فهرست مدلهای شبیهسازی کووید-۱۹
- دنیاگیری کووید-۱۹ در ایران
- همهگیری طاعون در ایران (۱۱۵۱-۱۱۵۲)
- واکسیناسیون کووید-۱۹ در ایران
پیوند به بیرون[ویرایش]
- SIR model: Online experiments with JSXGraph
- "Simulating an epidemic". ۳آبی۱قهوهای. March 27, 2020 – via یوتیوب.
- Network Science, by Albert-Barabsi
- ↑ Barabasi، Albert. spreading phenomena.