
الگوریتم DPLL: تفاوت میان نسخهها
بدون خلاصۀ ویرایش |
بدون خلاصۀ ویرایش برچسبها: افزودن پیوند بیرونی به جای ویکیپیوند ویرایشگر دیداری: به ویرایشگر منبع تغییر داده شده |
||
| خط ۱: | خط ۱: | ||
'''الگوریتم DPLL''' (کوتهنوشت '''Davis–Putnam–Logemann–Loveland''') در منطق و علوم |
'''الگوریتم DPLL''' (کوتهنوشت '''Davis–Putnam–Logemann–Loveland''') در [[منطق]] و [[علوم رایانه]]، یک [[الگوریتم جستجو|الگوریتم جستجوی]] کامل و مبتنی بر [[روش پسگرد|پسگرد]] برای [[مسئله صدقپذیری دودویی|تصمیمگیری برای صدقپذیری]] [[حساب گزارهای|فرمولهای منطق گزارهای]] در [[فرم نرمال اشتراکی|حالت نرمال عطفی]] است، به عبارت دیگر الگوریتم DPLL دارد [[مسئله صدقپذیری دودویی|مساله CNF-SAT]] را حل می کند. |
||
این الگوریتم در سال 1961 توسط مارتین |
این الگوریتم در سال 1961 توسط [[مارتین دیویس]]، [[جرج لاگمن|جرج لاگِمن]]، و [[دونالد لاولند]] معرفی گردید، که یک روش اصلاحی برای [[:en:Davis–Putnam_algorithm|الگوریتم پیشین دیویس-پاتنام]] بود، که این الگوریتم یک فرایند مبتنی بر [[رزولوشن (منطق)|رزلوشن]] بود که توسط دیویس و [[هیلاری پاتنم]] در سال 1960 توسعه داده شد. بخصوص در نشریات قدیمی، به الگوریتم دیویس-پاتانم-لاولند، «روش دیویس-پاتنام» یا «الگوریتم DP» گفته می شد. نامهای معمولتر دیگری که این تفاوت را حفظ نموده اند، DLL و DPLL می باشند. |
||
بعد از حدود 50 سال، هنوز هم فرایند DPLL مبنایی برای موثرترین حلکنندههای کامل SAT می باشد. این الگوریتم، به تازگی برای اثبات قضیه خودکار برای قطعههایی از منطق مرتبه اول به روش الگوریتم DPLL(T) گسترش داده شده است. |
بعد از حدود 50 سال، هنوز هم فرایند DPLL مبنایی برای موثرترین حلکنندههای کامل SAT می باشد. این الگوریتم، به تازگی برای [[اثبات قضیه خودکار]] برای قطعههایی از [[منطق مرتبه اول]] به روش الگوریتم [[:en:DPLL(T)|DPLL(T)]] گسترش داده شده است.<ref>{{Citation|contribution=Abstract DPLL and Abstract DPLL Modulo Theories|first1=Robert|last1=Nieuwenhuis|first2=Albert|last2=Oliveras|first3=Cesar|last3=Tinelli|year=2004|pages=36–50|title=Proceedings Int. Conf. on [[Logic for Programming, Artificial Intelligence, and Reasoning]], LPAR 2004|contribution-url=http://www.lsi.upc.edu/~roberto/papers/lpar04.pdf}}</ref> |
||
== پیادهسازی و کاربردها == |
== پیادهسازی و کاربردها == |
||
[[مسئله صدقپذیری دودویی|مسئله SAT]] هم از دیدگاه نظری و هم عملی مهم می باشد. در [[نظریه پیچیدگی محاسباتی|نظریه پیچیدگی]]، اولین مساله ای بود که ثابت شد که [[انپی کامل]] است. این مساله در موارد متنوع و گستردهای مثل «[[وارسی مدل]]»، «[[زمانبندی و برنامهریزی خودکار]]» و «[[:en:Diagnosis_(artificial_intelligence)|تشخیص در هوش مصنوعی]]» کاربرد دارد. |
|||
از این رو، این الگوریتم سال ها یک عنوان با پژوهش فراوان بوده است، و به صورت منظم صحنه رقابتهای زیادی بین حلکنندههای SAT بوده است. در سالهای اخیر، پیادهسازی های نوین DPLL مثل چاف و |
از این رو، این الگوریتم سال ها یک عنوان با پژوهش فراوان بوده است، و به صورت منظم صحنه رقابتهای زیادی بین [[:en:Boolean_satisfiability_problem#Algorithms_for_solving_SAT|حلکنندههای SAT]] بوده است.<ref>{{Citation|url=http://www.satcompetition.org/|title=The international SAT Competitions web page|publisher=sat! live}}</ref> در سالهای اخیر، پیادهسازی های نوین DPLL مثل [[:en:Chaff_algorithm|چاف و زدچاف]]،<ref>{{Citation|url=http://www.princeton.edu/~chaff/zchaff.html|title=zChaff website}}</ref><ref>{{Citation|url=http://www.princeton.edu/~chaff/|title=Chaff website}}</ref> [[:en:GRASP_(SAT_solver)|GRASP]] یا MiniSat<ref>{{Cite web|url=http://minisat.se/|title=Minisat website}}</ref> در مقام اول این رقابتها بوده اند. |
||
یک کاربرد دیگر که DPLL را درگیر نموده است، اثبات قضیه |
یک کاربرد دیگر که DPLL را درگیر نموده است، [[اثبات قضیه خودکار]]، یا [[:en:Satisfiability_modulo_theories|رضایت به پیمانه نظریات]] (SMT) بوده است، که یک نظریه SAT است که در آن [[متغیر گزارهای|متغیرهای گزارهای]] توسط فرمولهای دیگر [[نظریه ریاضیاتی|نظریه ی ریاضیاتی]] جایگزین شده اند. |
||
== الگوریتم == |
== الگوریتم == |
||
الگوریتم پسگرد اصلی توسط انتخاب یک لیترال، انتساب یک مقدار درستی بن آن، سادهسازی فرمول، و سپس بررسی بازگشتی این موضوع رخ می دهد که آیا فرمول سادهسازی شده صدقپذیر هست یا نه؛ اگر صدقپذیر بود، یعنی فرمول اصلی صدقپذیر است، در غیر این صورت، بررسی بازگشتی مشابهی باید با فرض مقدار درستی معکوس انجام شود. به این موضوع «قاعده جداسازی» گفته می شود، زیرا مساله را به دو زیرمساله سادهتر جداسازی می کند. گام سادهسازی به صورت اساسی همه بندهایی که تحت انتساب از فرمول، درست می شوند، و همه لیترالهایی که از بندهای باقیمانده نادرست می شوند، را حذف می کند. |
الگوریتم پسگرد اصلی توسط انتخاب یک لیترال، انتساب یک [[ارزش درستی|مقدار درستی]] بن آن، سادهسازی فرمول، و سپس بررسی بازگشتی این موضوع رخ می دهد که آیا فرمول سادهسازی شده صدقپذیر هست یا نه؛ اگر صدقپذیر بود، یعنی فرمول اصلی صدقپذیر است، در غیر این صورت، بررسی بازگشتی مشابهی باید با فرض مقدار درستی معکوس انجام شود. به این موضوع «قاعده جداسازی» گفته می شود، زیرا مساله را به دو زیرمساله سادهتر جداسازی می کند. گام سادهسازی به صورت اساسی همه بندهایی که تحت انتساب از فرمول، درست می شوند، و همه لیترالهایی که از بندهای باقیمانده نادرست می شوند، را حذف می کند. |
||
با استفاده حریصانه این قواعد در هر گام، الگوریتم DPLL روی الگوریتم پسگرد، افزایش می یابد: |
با استفاده حریصانه این قواعد در هر گام، الگوریتم DPLL روی الگوریتم پسگرد، افزایش می یابد: |
||
=== انتشار واحد === |
=== [[:en:Unit_propagation|انتشار واحد]] === |
||
:اگر بند یک بند واحد باشد، یعنی فقط شامل یک لیترال انتساب نیافته منفرد باشد، این بند فقط با انتساب مقدار لازم برای درست ساختن این لیترال، صادق می شود. از این رو هیچ گزینه ای لازم نیست. انتشار واحد شامل حذف هر بندی است که شامل لیترال بند واحد است و نیز شامل حذف مکمل لیترال بند واحد از هر بندی است که شامل آن مکمل است. در عمل این کار معمولا منجر به فروریختن قطعی واحدها می شود، از این رو از قسمت بزرگی از فضای جستجوی اولیه جلوگیری می شود. |
|||
=== حذف لیترال خالص === |
=== حذف لیترال خالص === |
||
:یک لیترال موقعی خالص است که در فرمول فقط یک جهت قطبیت داشته باشد. یک لیترال خالص را همیشه می توان به صورتی انتساب داد که همه بندهای شامل کننده اش را «درست» کند. از این رو اگر به این شیوه انتساب داده شود، این بندها دیگر جستجو را محدودسازی نمی کنند، و قابل حذف می شوند. |
|||
یک انتساب جزئی داده شده موقعی صدقناپذیری اش تشخیص داده می شود که یک بند خالی شود، یعنی همه متغیرهایش به شیوه ای منتسب شوند که لیترالهای متناظر را نادرست کنند. صدقپذیری فرمول یا موقعی تشخیص داده می شود که همه متغیرها را انتساب دهیم اما بند خالی تولید نشود، یا در پیادهسازی های نوین، اگر همه بندها صادق شوند. صدقناپذیری کامل فرمول تنها پس از جستجوی جامع تشخیص داده می شود. |
|||
الگوریتم DPLL را می توان در شبه کد زیر خلاصه کرد، که در آن Φ همان فرمول CNF است: |
الگوریتم DPLL را می توان در شبه کد زیر خلاصه کرد، که در آن Φ همان فرمول [[فرم نرمال اشتراکی|CNF]] است: |
||
{{Algorithm-begin|name=DPLL}} |
{{Algorithm-begin|name=DPLL}} |
||
| خط ۴۰: | خط ۴۱: | ||
''l'' ← ''choose-literal''(Φ); |
''l'' ← ''choose-literal''(Φ); |
||
'''return''' ''DPLL''(Φ '''∧''' {l}) '''or''' ''DPLL''(Φ '''∧''' {not(l)}); |
'''return''' ''DPLL''(Φ '''∧''' {l}) '''or''' ''DPLL''(Φ '''∧''' {not(l)}); |
||
{{Algorithm-end}}در این شبهکد<code>unit-propagate(l, Φ)</code> و <code>pure-literal-assign(l, Φ)</code> توابعی هستند که نتیجه اعمال انتشار واحد و قاعده لیترال خالص را برای لیترال l و فرمول Φ به ترتیب برمی گردانند. به زبان دیگر، این توابع در فرمول Φ هر رخداد l را به «درست» و هر رخداد not l را با «نادرست» جایگزین می کنند، و سپس فرمول نتیجه شده را سادهسازی می کنند. or موجود در عبارت return یک عملگر اتصال کوتاه است. Φ '''∧''' {l} نشان دهنده نتیجه سادهسازی شده جایگزینی «درست» برای l در Φ است. |
{{Algorithm-end}}در این شبهکد<code>unit-propagate(l, Φ)</code> و <code>pure-literal-assign(l, Φ)</code> توابعی هستند که نتیجه اعمال انتشار واحد و قاعده لیترال خالص را برای لیترال <code>l</code> و فرمول <code>Φ</code> به ترتیب برمی گردانند. به زبان دیگر، این توابع در فرمول <code>Φ</code> هر رخداد <code>l</code> را به «درست» و هر رخداد <code>not l</code> را با «نادرست» جایگزین می کنند، و سپس فرمول نتیجه شده را سادهسازی می کنند. <code>'''or'''</code> موجود در عبارت <code>'''return'''</code> یک [[ارزیابی اتصال کوتاه|عملگر اتصال کوتاه]] است. <code>Φ '''∧''' {l}</code> نشان دهنده نتیجه سادهسازی شده جایگزینی «درست» برای <code>l</code> در <code>Φ</code> است. |
||
این الگوریتم در یکی از این دو حالت خاتمه می یابد. یا اینکه فرمول CNF ای با نام Φ پیدا می شود که شامل مجموعه سازگاری از لیترال ها باشد، یعنی هیچ l و ¬l ای برای لیترال l در فرمول موجود نباشد. اگر این موضوع رخ دهد، متغیرها را به صورت بدیهی با تنظیم آنها به قطبیت متناظر لیترال شامل شونده در ارزیابی صادق می شوند. در غیر این صورت، موقعی که فرمول شامل یک بند خالی باشد، این بند به صورت پوچ «نادرست» است، زیرا یک فصل نیاز دارد که حداقل یک عضو درست دارد تا مجموعه کلی درست شود. در این حالت، وجود چنین بندی به معنی آن است که فرمول (که به صورت عطف همه بندها ارزیابی می شود) را نمی توان «درست» ارزیابی کرد، و فرمول باید صدقناپذیر باشد. |
این الگوریتم در یکی از این دو حالت خاتمه می یابد. یا اینکه فرمول CNF ای با نام <code>Φ</code> پیدا می شود که شامل مجموعه سازگاری از لیترال ها باشد، یعنی هیچ <code>l</code> و <code>¬l</code> ای برای لیترال <code>l</code> در فرمول موجود نباشد. اگر این موضوع رخ دهد، متغیرها را به صورت بدیهی با تنظیم آنها به قطبیت متناظر لیترال شامل شونده در ارزیابی صادق می شوند. در غیر این صورت، موقعی که فرمول شامل یک بند خالی باشد، این بند به صورت پوچ «نادرست» است، زیرا یک فصل نیاز دارد که حداقل یک عضو درست دارد تا مجموعه کلی درست شود. در این حالت، وجود چنین بندی به معنی آن است که فرمول (که به صورت عطف همه بندها ارزیابی می شود) را نمی توان «درست» ارزیابی کرد، و فرمول باید صدقناپذیر باشد. |
||
شبهکد تابع DPLL فقط این موضوع را برمی گرداند که آیا انتساب نهایی برای فرمول برآورده می کند یا نه. در یک پیادهسازی واقعی، یک انتساب نیمه صادق نیز معمولا موفقیت را برمی گرداند؛ این موضوع از مجموعه سازگار لیترال های بیانیه if اول در تابع قابل مشتق کردن است. |
شبهکد تابع DPLL فقط این موضوع را برمی گرداند که آیا انتساب نهایی برای فرمول برآورده می کند یا نه. در یک پیادهسازی واقعی، یک انتساب نیمه صادق نیز معمولا موفقیت را برمی گرداند؛ این موضوع از مجموعه سازگار لیترال های بیانیه <code>if</code> اول در تابع قابل مشتق کردن است. |
||
الگوریتم دیویس-لاگمن-لاولند به گزینه «لیترال انتشعابی» بستگی دارد، که همان لیترالی است که در گام پسگرد درنظرگرفته شده است. و این موضوع، یعنی الگوریتم DPLL یک الگوریتم دقیق نیست، بلکه خانواده ای از الگوریتمها است، که هر عضو آن خانواده یک روش ممکن برای انتخاب لیترال انشعاب دارد. کارایی الگوریتم به شدت توسط نحوه انتخاب گزینه لیترال انشعاب تاثیر می پذیرد: نمونه هایی وجود دارد که در آن زمان اجرایی ثابت است، و همچنین در نمونه هایی نمایی است، این موضوع بستگی به نحوه انتخاب لیترال های انشعابی دارد. به این توابع انتخابی، «توابع اکتشاف»، یا «اکتشاف برای انشعاب» هم گفته می شود. |
الگوریتم دیویس-لاگمن-لاولند به گزینه «لیترال انتشعابی» بستگی دارد، که همان لیترالی است که در گام پسگرد درنظرگرفته شده است. و این موضوع، یعنی الگوریتم DPLL یک الگوریتم دقیق نیست، بلکه خانواده ای از الگوریتمها است، که هر عضو آن خانواده یک روش ممکن برای انتخاب لیترال انشعاب دارد. کارایی الگوریتم به شدت توسط نحوه انتخاب گزینه لیترال انشعاب تاثیر می پذیرد: نمونه هایی وجود دارد که در آن زمان اجرایی ثابت است، و همچنین در نمونه هایی نمایی است، این موضوع بستگی به نحوه انتخاب لیترال های انشعابی دارد. به این توابع انتخابی، «[[الگوریتم جستجوی کاشف|توابع اکتشاف]]»، یا «اکتشاف برای انشعاب» هم گفته می شود.<ref>{{Cite book | last1 = Marques-Silva | first1 = João P.| chapter = The Impact of Branching Heuristics in Propositional Satisfiability Algorithms | doi = 10.1007/3-540-48159-1_5 | title = Progress in Artificial Intelligence: 9th Portuguese Conference on Artificial Intelligence, EPIA '99 Évora, Portugal, September 21–24, 1999 Proceedings | editor1-first = Pedro | editor1-last = Barahona | editor2-first = José J. | editor2-last = Alferes| series = [[Lecture Notes in Computer Science|LNCS]] | volume = 1695 | pages = 62–63 | year = 1999 | isbn = 978-3-540-66548-9 }}</ref> |
||
=== نحوه تصور === |
=== نحوه تصور === |
||
| خط ۵۶: | خط ۵۷: | ||
یک مثال با تصور یک الگوریتم DPLL که پسگرد زمانی دارد: |
یک مثال با تصور یک الگوریتم DPLL که پسگرد زمانی دارد: |
||
<gallery> |
|||
Image:Dpll1.png|All clauses making a CNF formula |
|||
Image:Dpll2.png|Pick a variable |
|||
Image:Dpll3.png|Make a decision, variable a = False (0), thus green clauses becomes True |
|||
Image:Dpll4.png|After making several decisions, we find an [[implication graph]] that leads to a conflict. |
|||
Image:Dpll5.png|Now backtrack to immediate level and by force assign opposite value to that variable |
|||
Image:Dpll6.png|But a forced decision still leads to another conflict |
|||
Image:Dpll7.png|Backtrack to previous level and make a forced decision |
|||
Image:Dpll8.png|Make a new decision, but it leads to a conflict |
|||
Image:Dpll9.png|Make a forced decision, but again it leads to a conflict |
|||
Image:Dpll10.png|Backtrack to previous level |
|||
Image:Dpll11.png|Continue in this way and the final implication graph |
|||
</gallery> |
|||
== کارهای جدید روی الگوریتم == |
== کارهای جدید روی الگوریتم == |
||
| خط ۶۲: | خط ۷۷: | ||
# تعریف سیاستهای متنوع برای انتخاب لیترال انتشعاب. |
# تعریف سیاستهای متنوع برای انتخاب لیترال انتشعاب. |
||
# تعریف ساختمان داده های جدید برای سریعسازی الگوریتم، مخصوصا بخش مرتبط با '''انتشار واحد'''. |
# تعریف ساختمان داده های جدید برای سریعسازی الگوریتم، مخصوصا بخش مرتبط با '''انتشار واحد'''. |
||
# تعریف انواع الگوریتم پسگرد اصلی. که در این جهت آخر شامل «پسگردهای غیرزمانی» (که به آن پسپرش گفته می شود) و یادگیری بند است. این اصلاحات توصیف کننده یک روش پسگرد بعد از رسیدن به یک بند متعارض است که بند ریشه ای (انتساب به متغیرها) در تعارض را با هدف جلوگیری از رسیدن به تعارض مشابه به صورت مجدد، «یاد می گیرد». حلکننده های نتیجه شده SAT که حالت یادگیری بند مبتنی بر تعارض دارند، موضوع پژوهش های تازه زیادی در سال 2014 بوده است. |
# تعریف انواع الگوریتم پسگرد اصلی. که در این جهت آخر شامل «پسگردهای غیرزمانی» (که به آن [[پسپرش (الگوریتم)|پسپرش]] گفته می شود) و [https://en.wikipedia.org/wiki/Conflict-driven_clause_learning یادگیری بند] است. این اصلاحات توصیف کننده یک روش پسگرد بعد از رسیدن به یک بند متعارض است که بند ریشه ای (انتساب به متغیرها) در تعارض را با هدف جلوگیری از رسیدن به تعارض مشابه به صورت مجدد، «یاد می گیرد». حلکننده های نتیجه شده SAT که حالت [https://en.wikipedia.org/wiki/Conflict-driven_clause_learning یادگیری بند مبتنی بر تعارض] دارند، موضوع پژوهش های تازه زیادی در سال 2014 بوده است. |
||
یک الگوریتم جدیدتر از سال 1990، روش استالمارک است. از این رو از سال 1986 نمودارهای تصمیم دودویی (با مرتبه پایین) برای حل SAT استفاده شده است. |
یک الگوریتم جدیدتر از سال 1990، [[روش استالمارک]] است. از این رو از سال 1986 [[نمودار تصمیم دودویی|نمودارهای تصمیم دودویی]] (با مرتبه پایین) برای حل SAT استفاده شده است. |
||
== ارتباط با دیگر مفاهیم == |
== ارتباط با دیگر مفاهیم == |
||
اجرای الگوریتمهای مبتنی بر DPLL روی نمونههای صدقناپذیر متناظر است با اثبات های انکار وجود رزلوشن درختی. |
اجرای الگوریتمهای مبتنی بر DPLL روی نمونههای صدقناپذیر متناظر است با اثبات های انکار وجود [[رزولوشن (منطق)|رزلوشن]] درختی. |
||
== پانویس == |
== پانویس == |
||
{{پانویس}} |
{{پانویس}} |
||
نسخهٔ ۴ مهٔ ۲۰۲۱، ساعت ۱۲:۵۴
الگوریتم DPLL (کوتهنوشت Davis–Putnam–Logemann–Loveland) در منطق و علوم رایانه، یک الگوریتم جستجوی کامل و مبتنی بر پسگرد برای تصمیمگیری برای صدقپذیری فرمولهای منطق گزارهای در حالت نرمال عطفی است، به عبارت دیگر الگوریتم DPLL دارد مساله CNF-SAT را حل می کند.
این الگوریتم در سال 1961 توسط مارتین دیویس، جرج لاگِمن، و دونالد لاولند معرفی گردید، که یک روش اصلاحی برای الگوریتم پیشین دیویس-پاتنام بود، که این الگوریتم یک فرایند مبتنی بر رزلوشن بود که توسط دیویس و هیلاری پاتنم در سال 1960 توسعه داده شد. بخصوص در نشریات قدیمی، به الگوریتم دیویس-پاتانم-لاولند، «روش دیویس-پاتنام» یا «الگوریتم DP» گفته می شد. نامهای معمولتر دیگری که این تفاوت را حفظ نموده اند، DLL و DPLL می باشند.
بعد از حدود 50 سال، هنوز هم فرایند DPLL مبنایی برای موثرترین حلکنندههای کامل SAT می باشد. این الگوریتم، به تازگی برای اثبات قضیه خودکار برای قطعههایی از منطق مرتبه اول به روش الگوریتم DPLL(T) گسترش داده شده است.[۱]
پیادهسازی و کاربردها
مسئله SAT هم از دیدگاه نظری و هم عملی مهم می باشد. در نظریه پیچیدگی، اولین مساله ای بود که ثابت شد که انپی کامل است. این مساله در موارد متنوع و گستردهای مثل «وارسی مدل»، «زمانبندی و برنامهریزی خودکار» و «تشخیص در هوش مصنوعی» کاربرد دارد.
از این رو، این الگوریتم سال ها یک عنوان با پژوهش فراوان بوده است، و به صورت منظم صحنه رقابتهای زیادی بین حلکنندههای SAT بوده است.[۲] در سالهای اخیر، پیادهسازی های نوین DPLL مثل چاف و زدچاف،[۳][۴] GRASP یا MiniSat[۵] در مقام اول این رقابتها بوده اند.
یک کاربرد دیگر که DPLL را درگیر نموده است، اثبات قضیه خودکار، یا رضایت به پیمانه نظریات (SMT) بوده است، که یک نظریه SAT است که در آن متغیرهای گزارهای توسط فرمولهای دیگر نظریه ی ریاضیاتی جایگزین شده اند.
الگوریتم
الگوریتم پسگرد اصلی توسط انتخاب یک لیترال، انتساب یک مقدار درستی بن آن، سادهسازی فرمول، و سپس بررسی بازگشتی این موضوع رخ می دهد که آیا فرمول سادهسازی شده صدقپذیر هست یا نه؛ اگر صدقپذیر بود، یعنی فرمول اصلی صدقپذیر است، در غیر این صورت، بررسی بازگشتی مشابهی باید با فرض مقدار درستی معکوس انجام شود. به این موضوع «قاعده جداسازی» گفته می شود، زیرا مساله را به دو زیرمساله سادهتر جداسازی می کند. گام سادهسازی به صورت اساسی همه بندهایی که تحت انتساب از فرمول، درست می شوند، و همه لیترالهایی که از بندهای باقیمانده نادرست می شوند، را حذف می کند.
با استفاده حریصانه این قواعد در هر گام، الگوریتم DPLL روی الگوریتم پسگرد، افزایش می یابد:
انتشار واحد
- اگر بند یک بند واحد باشد، یعنی فقط شامل یک لیترال انتساب نیافته منفرد باشد، این بند فقط با انتساب مقدار لازم برای درست ساختن این لیترال، صادق می شود. از این رو هیچ گزینه ای لازم نیست. انتشار واحد شامل حذف هر بندی است که شامل لیترال بند واحد است و نیز شامل حذف مکمل لیترال بند واحد از هر بندی است که شامل آن مکمل است. در عمل این کار معمولا منجر به فروریختن قطعی واحدها می شود، از این رو از قسمت بزرگی از فضای جستجوی اولیه جلوگیری می شود.
حذف لیترال خالص
- یک لیترال موقعی خالص است که در فرمول فقط یک جهت قطبیت داشته باشد. یک لیترال خالص را همیشه می توان به صورتی انتساب داد که همه بندهای شامل کننده اش را «درست» کند. از این رو اگر به این شیوه انتساب داده شود، این بندها دیگر جستجو را محدودسازی نمی کنند، و قابل حذف می شوند.
یک انتساب جزئی داده شده موقعی صدقناپذیری اش تشخیص داده می شود که یک بند خالی شود، یعنی همه متغیرهایش به شیوه ای منتسب شوند که لیترالهای متناظر را نادرست کنند. صدقپذیری فرمول یا موقعی تشخیص داده می شود که همه متغیرها را انتساب دهیم اما بند خالی تولید نشود، یا در پیادهسازی های نوین، اگر همه بندها صادق شوند. صدقناپذیری کامل فرمول تنها پس از جستجوی جامع تشخیص داده می شود.
الگوریتم DPLL را می توان در شبه کد زیر خلاصه کرد، که در آن Φ همان فرمول CNF است:
Algorithm DPLL
Input: A set of clauses Φ.
Output: A Truth Value.
function DPLL(Φ)
if Φ is a consistent set of literals then
return true;
if Φ contains an empty clause then
return false;
for every unit clause {l} in Φ do
Φ ← unit-propagate(l, Φ);
for every literal l that occurs pure in Φ do
Φ ← pure-literal-assign(l, Φ);
l ← choose-literal(Φ);
return DPLL(Φ ∧ {l}) or DPLL(Φ ∧ {not(l)});
- "←" denotes assignment. For instance, "largest ← item" means that the value of largest changes to the value of item.
- "return" terminates the algorithm and outputs the following value.
در این شبهکدunit-propagate(l, Φ) و pure-literal-assign(l, Φ) توابعی هستند که نتیجه اعمال انتشار واحد و قاعده لیترال خالص را برای لیترال l و فرمول Φ به ترتیب برمی گردانند. به زبان دیگر، این توابع در فرمول Φ هر رخداد l را به «درست» و هر رخداد not l را با «نادرست» جایگزین می کنند، و سپس فرمول نتیجه شده را سادهسازی می کنند. or موجود در عبارت return یک عملگر اتصال کوتاه است. Φ ∧ {l} نشان دهنده نتیجه سادهسازی شده جایگزینی «درست» برای l در Φ است.
این الگوریتم در یکی از این دو حالت خاتمه می یابد. یا اینکه فرمول CNF ای با نام Φ پیدا می شود که شامل مجموعه سازگاری از لیترال ها باشد، یعنی هیچ l و ¬l ای برای لیترال l در فرمول موجود نباشد. اگر این موضوع رخ دهد، متغیرها را به صورت بدیهی با تنظیم آنها به قطبیت متناظر لیترال شامل شونده در ارزیابی صادق می شوند. در غیر این صورت، موقعی که فرمول شامل یک بند خالی باشد، این بند به صورت پوچ «نادرست» است، زیرا یک فصل نیاز دارد که حداقل یک عضو درست دارد تا مجموعه کلی درست شود. در این حالت، وجود چنین بندی به معنی آن است که فرمول (که به صورت عطف همه بندها ارزیابی می شود) را نمی توان «درست» ارزیابی کرد، و فرمول باید صدقناپذیر باشد.
شبهکد تابع DPLL فقط این موضوع را برمی گرداند که آیا انتساب نهایی برای فرمول برآورده می کند یا نه. در یک پیادهسازی واقعی، یک انتساب نیمه صادق نیز معمولا موفقیت را برمی گرداند؛ این موضوع از مجموعه سازگار لیترال های بیانیه if اول در تابع قابل مشتق کردن است.
الگوریتم دیویس-لاگمن-لاولند به گزینه «لیترال انتشعابی» بستگی دارد، که همان لیترالی است که در گام پسگرد درنظرگرفته شده است. و این موضوع، یعنی الگوریتم DPLL یک الگوریتم دقیق نیست، بلکه خانواده ای از الگوریتمها است، که هر عضو آن خانواده یک روش ممکن برای انتخاب لیترال انشعاب دارد. کارایی الگوریتم به شدت توسط نحوه انتخاب گزینه لیترال انشعاب تاثیر می پذیرد: نمونه هایی وجود دارد که در آن زمان اجرایی ثابت است، و همچنین در نمونه هایی نمایی است، این موضوع بستگی به نحوه انتخاب لیترال های انشعابی دارد. به این توابع انتخابی، «توابع اکتشاف»، یا «اکتشاف برای انشعاب» هم گفته می شود.[۶]
نحوه تصور
در سال 1961 دیویس، لاگمن، لاومن این الگوریتم را ایجاد کردند. بعضی از ویژگی های این الگوریتم از این قرار است:
- بر اساس جستجو می باشد.
- مبنای تقریبا همه حلکننده های SAT نوین است.
- از پسگردهایی که یادگیرنده اند یا غیرزمانی اند استفاده نمی کند.
یک مثال با تصور یک الگوریتم DPLL که پسگرد زمانی دارد:
-
 All clauses making a CNF formula
All clauses making a CNF formula -
 Pick a variable
Pick a variable -
 Make a decision, variable a = False (0), thus green clauses becomes True
Make a decision, variable a = False (0), thus green clauses becomes True -
 After making several decisions, we find an implication graph that leads to a conflict.
After making several decisions, we find an implication graph that leads to a conflict. -
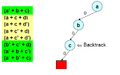 Now backtrack to immediate level and by force assign opposite value to that variable
Now backtrack to immediate level and by force assign opposite value to that variable -
 But a forced decision still leads to another conflict
But a forced decision still leads to another conflict -
 Backtrack to previous level and make a forced decision
Backtrack to previous level and make a forced decision -
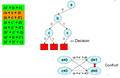 Make a new decision, but it leads to a conflict
Make a new decision, but it leads to a conflict -
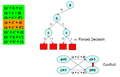 Make a forced decision, but again it leads to a conflict
Make a forced decision, but again it leads to a conflict -
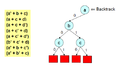 Backtrack to previous level
Backtrack to previous level -
 Continue in this way and the final implication graph
Continue in this way and the final implication graph











کارهای جدید روی الگوریتم
در سالهای دهه 2010، کار روی بهبود الگوریتم در سه جهت انجام شد:
- تعریف سیاستهای متنوع برای انتخاب لیترال انتشعاب.
- تعریف ساختمان داده های جدید برای سریعسازی الگوریتم، مخصوصا بخش مرتبط با انتشار واحد.
- تعریف انواع الگوریتم پسگرد اصلی. که در این جهت آخر شامل «پسگردهای غیرزمانی» (که به آن پسپرش گفته می شود) و یادگیری بند است. این اصلاحات توصیف کننده یک روش پسگرد بعد از رسیدن به یک بند متعارض است که بند ریشه ای (انتساب به متغیرها) در تعارض را با هدف جلوگیری از رسیدن به تعارض مشابه به صورت مجدد، «یاد می گیرد». حلکننده های نتیجه شده SAT که حالت یادگیری بند مبتنی بر تعارض دارند، موضوع پژوهش های تازه زیادی در سال 2014 بوده است.
یک الگوریتم جدیدتر از سال 1990، روش استالمارک است. از این رو از سال 1986 نمودارهای تصمیم دودویی (با مرتبه پایین) برای حل SAT استفاده شده است.
ارتباط با دیگر مفاهیم
اجرای الگوریتمهای مبتنی بر DPLL روی نمونههای صدقناپذیر متناظر است با اثبات های انکار وجود رزلوشن درختی.
پانویس
- ↑ Nieuwenhuis, Robert; Oliveras, Albert; Tinelli, Cesar (2004), "Abstract DPLL and Abstract DPLL Modulo Theories" (PDF), Proceedings Int. Conf. on Logic for Programming, Artificial Intelligence, and Reasoning, LPAR 2004, pp. 36–50
- ↑ The international SAT Competitions web page, sat! live
- ↑ zChaff website
- ↑ Chaff website
- ↑ "Minisat website".
- ↑ Marques-Silva, João P. (1999). "The Impact of Branching Heuristics in Propositional Satisfiability Algorithms". In Barahona, Pedro; Alferes, José J. (eds.). Progress in Artificial Intelligence: 9th Portuguese Conference on Artificial Intelligence, EPIA '99 Évora, Portugal, September 21–24, 1999 Proceedings. LNCS. Vol. 1695. pp. 62–63. doi:10.1007/3-540-48159-1_5. ISBN 978-3-540-66548-9.
منابع
مشارکتکنندگان ویکیپدیا. «DPLL algorithm». در دانشنامهٔ ویکیپدیای انگلیسی، بازبینیشده در ۴ مهٔ ۲۰۲۱.