
مدلهای انتزاعی پایگاه دادهها
این مقاله نیازمند تمیزکاری است. لطفاً تا جای امکان آنرا از نظر املا، انشا، چیدمان و درستی بهتر کنید، سپس این برچسب را بردارید. محتویات این مقاله ممکن است غیر قابل اعتماد و نادرست یا جانبدارانه باشد یا قوانین حقوق پدیدآورندگان را نقض کرده باشد. |
این مقاله نیازمند ویکیسازی است. لطفاً با توجه به راهنمای ویرایش و شیوهنامه، محتوای آن را بهبود بخشید. |
مدل انتزاعی پایگاه دادهها یا بهطور خلاصه مدل دادهای نوعی از مدل دادهها است که تعیین کنندهٔ ساختار منطقی پایگاه داده بوده و اساساً تعیین میکند که دادهها چگونه ذخیره، سازماندهی و دستکاری شوند. پرطرفدارترین نمونه از مدل پایگاه داده نوع رابطه ای است که از قالب جدولی بهره میبرد.
مدلهای رایج داده در پایگاه دادهها
[ویرایش]- مدل داده سلسله مراتبی
- مدل شبکه ای
- مدل رابطه ای
- مدل موجودیت-رابطه
- مدل شیءای
- مدل سندگرا
- مدل موجودیت-خصیصه-مقدار
- طرحواره ستاره ای
یک پایگاه داده شیء- رابطه ای ترکیبی است از دو ساختار مرتبط یعنی مدل شیئی و مدل رابطهای.
مدل فیزیکی داده دربردارندهٔ دو نوع زیر است:
- نمایه واژگون یا Inverted Index
- پروندهٔ تخت یا Flat file
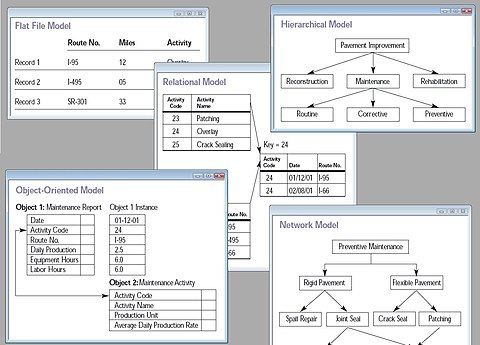
۵ نمونه از مدلهای پایگاه داده

دیگر انواع مدلها شامل:
- مدل داده شرکت پذیر یا Associative Model
- مدل چند بعدی
- مدل چند مقداره
- مدل معنایی
- پایگاه داده XML
- نمودارمشخص یا گراف نامدار
- ذخیره سهگانه یا تریپلاستور
روابط و کارکردها
[ویرایش]یک سامانه مدیر پایگاه داده فراهم کنندهٔ یک یا تعداد بیشتری از مدلهای پنجگانه است. ساختار بهینه بستگی به آرایش آغازین دادههای کاربرد و نیز نیازهای کاربردی دارد که عبارتند از: آهنگ تراکنش (سرعت)، اطمینان پذیری، نگهداشت پذیری (maintainability)، مقیاس پذیری و هزینه. بیشتر نرمافزارهای مدیریت پایگاه داده بر پایهٔ یکی از مدلهای داده بنا میشوند اگرچه امکان پشتیبانی از دیگر انواع مدلها در این نرمافزارها نیز وجود دارد.
مدلهای فیزیکی گوناگون توانایی پیادهسازی هر نوع مدل منطقی را دارا هستند. از آنجایی که نوع انتخاب تأثیر قابل توجه بر کارایی دارد اغلب نرمافزارهای پایگاه داده سطح مشخصی از قابلیت تغییر در پیادهسازی مدل فیزیکی را در اختیار کاربر قرار میدهند بدین معنا که کاربر میتواند تغییرات جزئی در چگونگی پیادهسازی اعمال کند البته در سطحی محدود.
یک مدل تنها روشی برای ساختاردهی به دادهها نیست بلکه تعریف کنندهٔ گروهی از عملیاتها است که میتوانند بر روی دادهها اعمال شوند. به عنوان نمونه در مدل رابطه ای عملیاتی همچون select (project) and join تعریف میشود. اگر چه ممکن است این عملیاتها به ویژه در مورد کوئری آشکار نباشند ولیکن همچنان مبنایی را فراهم میکنند که بر آن پرس و جوی زبان (query language) استوار میشود.
مدل تخت
[ویرایش]
مدل (یا جدول) تخت دربردارندهٔ یک آرایهٔ دوبعدی از عناصر دادهاست که در آن فرض میشود که همهٔ عضوهای یک ستون مشخص مشابه بوده و همهٔ عضوهای یک ردیف با یکدیگر مرتبطاند. نمونه ای از این همانندی را میتوان در ستونهای نام و گذرواژه که ممکن است به عنوان بخشی از سامانهٔ امنیتی پایگاه داده بکار گرفته شوند مشاهد نمود. هر ردیف در چنین سامانه ای گذرواژهٔ مربوط به یک کاربر را در خود جای میدهد. هر ستون جدول دارای نوع مشخصی دادهاست که تعریف میکند آن داده از کدام یک از انواع نویسه (کاراکتر)، تاریخ و زمان، عدد صحیح یا اعشاری شناور است. چنین قالبی از جدول پیش نیاز یک مدل رابطه ای بهشمار میرود.
نخستین مدلهای داده
[ویرایش]این مدلها در دههٔ ۱۹۶۰ و ۱۹۷۰ پرطرفدار بوده ولی امروزه تنها در سامانههای قدیمی که هنوز به دلیل هزینهٔ بالا جایگزین نشدهاند دیده میشوند. مشخصهٔ اصلی آنها امکان ناوبری پایگاه داده با اتصالات نیرومند میان مدلهای منطقی و فیزیکی بوده و البته از دیدگاه استقلال دادهها دارای کاستیهایی هستند.
مدل سلسله مراتبی
[ویرایش]
در یک مدل سلسله مراتبی دادهها در یک ساختار درخت مانند سازماندهی شده که در آن هر رکورد دارای یک والد است. یک ستون مرتبسازی نیز رکوردهای خواهر/برادر را مرتب نگه میدارد. ساختار سلسله مراتبی در دوران سامانههای مدیریت پایگاه داده ابررایانهها (mainframe) از جمله در سامانههای مدیریت اطلاعات (IMS) به وسیلهٔ IBM بهطور گستردهای استفاده میشد و هماکنون الگویی از ساختار سندهای XML است. این ساختار امکان یک رابطهٔ تک-به-بسیار میان دو نوع داده را فراهم میکند. چنین ساختاری برای نشان دادن بسیاری از روابط در جهان واقعی نیز بسیار کارآمد است مانند دستور پخت، جدول محتویات، ترتیب پارگرافها/ابیات شعر، یا هر نوع اطلاعات تودرتو.
چنین سلسله مراتبی به صورت ترتیبی فیزیکی از رکوردها در حافظه بکار گرفته میشود. دستیابی به رکوردها با ترکیبی از یک نشانگر و پویش پی در پی در درون ساختار دادهها انجام میپذیرد. از اینرو ساختار سلسله مراتبی برای برخی از عملیاتهای پایگاه داده در هنگامی که مسیر کامل (در مقایسه با پیوندک (لینک) رو به بالا و ستون مرتبسازی) ذخیرهسازی آن رکورد مشخص نباشد روشی ناکارآمد است. چنین محدودیتهایی با افزودن سلسله مراتب منطقی به سلسله مراتب فیزیکی مبنا در ویرایشهای بعدی IMS مرتفع گردید.
مدل شبکه ای
[ویرایش]
مدل شبکه ای تعمیم یافتهٔ ساختار سلسله مراتبی بوده و بنابراین امکان برقراری رابطهٔ چند- به -چند را در ساختار درخت مانندی با امکان داشتن چندین والد را فراهم میکند. این مدل پیش از این که با مدل رابطه ای جایگزین شود پرطرفدارترین مدل داده بود و مشخصات آن بوسیلهٔ CODASYL تعریف شدهاست. مدل شبکه ای با بهرهگیری از دو مفهوم دادهها را سازماندهی میکند که عبارتند از «رکوردها» و «مجموعهها» (sets). رکوردها همانند زبان برنامهنویسی کوبول دارای ستونهایی هستند (که ممکن است بهطور سلسله مراتبی سازماندهی شده باشند). مجموعهها (نباید با مجموعههای ریاضی اشتباه گرفته شوند) روابط یک- به- چند میان رکوردها تعریف میکنند: مانند یک مالک و بسیاری عضو. یک رکورد میتواند در هر تعداد مجموعه یک مالک و در بسیاری از مجموعهها عضو باشد.
الگوی کاری کاربران پایگاه دادهها را در سطح منطقی مشخص میکند. شگردهای مختلفی برای مدلهای دادهای وجود دارد. برای هر یک از مدلهای منطقی اجراهای فیزیکی مختلفی قابل پیادهسازی است و سطوح کنترل مختلفی در انطباق فیزیکی برای کاربران مهیا میکند. یک انتخاب مناسب تأثیر مؤثری بر اجرا دارد. یک مدل دادهای تنها شیوه ساختمان بندی دادهها نیست بلکه معمولاً به صورت مجموعهای از عملیاتها که میتواند روی دادهها اجرا شود تعریف میشوند.
مدل تخت
[ویرایش]مدل تخت یا جدولی تشکیل شدهاست از یک آرایه دو بعدی با عناصر دادهای که همه اجزای یک ستون به صورت دادههای مشابه فرض میشود و همه عناصر یک سطر با هم در ارتباط هستند. برای نمونه در ستونهایی که برای نام کاربری و رمز عبور در جزئی از سیستمهای پایگاه دادهای امنیتی مورد استفاده قرار میگیرد هر سطر شامل رمز عبوری است که مخصوص یک کاربر خاص است. ستونهای جدول که با آن در ارتباط هستند به صورت داده کاراکتری، اطلاعات زمانی، عدد صحیح یا اعداد ممیز شناور تعریف میشوند. این مدل پایه برنامههای محاسباتی است. پایگاه داده ه با فایلهای تخت به سادگی توسط فایلهای متنی تعریف میشوند. هر رکورد یک خط است و فیلدها به کمک جدا کنندههایی از هم مجزا میشوند.
مدل سلسله مراتبی
[ویرایش]در این مدل اطلاعات به وسیلهٔ اشاره گرهایی که توسط کاربر و در سطح فیزیکی تعریف میشوند به هم متصل میشوند. اطلاعات در این مدل به شکل یک درخت شبیهسازی میشوند؛ مثلاً اگر هنگام طراحی کلاس در سطح بالای دانشجو قرار گیرد، از هر دانشجو تعدادی اشاره گر به کلاسهایی که وی در آن ثبت نام کردهاست، اشاره خواهند کرد؛ بنابراین زمان گزارشگیری نامتقارن خواهد شد و زمان پیدا کردن کلاسهایی که یک دانشجو دارد بسیار کوتاه و زمان پیدا کردن دانشجویانی که در یک کلاس ثبت نام نمودهاند بسیار طولانی خواهد بود. طراحی چنین پایگاهی بسیار مشکل است. با وجود تمام این معایب کارایی این مدل از فایلهای تخت بسیار بیشتر است.
مدل شبکهای
[ویرایش]در سال ۲۰۱۰ و در کنفرانس زبانهای سیستمهای دادهای توسط ارائه شد. در سال۲۰۱۰ مجدداً مطرح شد و اساس کار پایگاه دادهای قرار گرفت و در اوایل دهه ۸۰ با ثبت آن درسازمان بینالمللی استانداردهای جهانی یا ISO به اوج رسید.
مدل شبکهای بر پایه دو سازه مهم یعنی مجموعهها و رکوردها ساخته میشود و برخلاف روش سلسله مراتبی که از درخت استفاده میکند، گراف را به کار میگیرد. مزیت این روش بر سلسله مراتبی این است که مدلهای ارتباطی طبیعی بیشتری را بین موجودیتها فراهم میکند. علیرغم این مزیتها به دو دلیل اساسی این مدل با شکست مواجه شد: اول اینکه شرکت IBM با تولید محصولات IMS و DL/I که بر پایه مدل سلسله مراتبی است این مدل را نادیده گرفت. دوم اینکه سرانجام مدل رابطهای جای آن را گرفت چون سطح بالاتر و واضح تر بود. تا اوایل دهه ۸۰ به علت کارایی رابطهای سطح پایین مدل سلسله مراتبی و شبکهای پیشنهاد میشد که بسیاری از نیازهای آن زمان را برطرف میکرد. اما با سریعتر شدن سختافزار به علت قابلیت انعطاف و سودمندی بیشتر سیستمهای رابطهای به پیروزی رسیدند.
رکوردها در این مدل شامل فیلدهایی است (ممکن است همچون زبان COBOL به صورت سلسله مراتب اولویتی باشد). مجموعهها با ارتباط یک به چند بین رکوردها تعریف میشود: یک مالک و چند عضو. عملیاتهای مدل شبکهای از نوع هدایت کنندهاست: یک برنامه در موقعیت جاری خود باقی میماند و از یک رکورد به رکورد دیگر میرود هر گاه که ارتباطی بین آنها وجود داشته باشد. معمولاً از اشاره گر ها(pointers) برای آدرس دهی مستقیم به یک رکورد در دیسک استفاده میشود. با این تکنیک کارایی بازیابی اضافه میشود هر چند در نمایش ظاهری این مدل ضروری نیست.
مدل رابطهای
[ویرایش]این مدل اساس کار سامانه مدیریت پایگاه دادههای امروزی است.
مقاله اصلی: مدل رابطهای مدل رابطه ای (relational model) در سال ۱۹۷۰ توسط ریاضیدانی به نام Edgar.F.Codd طراحی شد. مدل داده پیشنهادی یک مدل منطقی بر مبنای ریاضیات است که از منطق گزارهها و تئوری مجموعهها به عنوان زیربنا استفاده شدهاست.
یک پایگاه داده رابطه ای (relational database) پایگاه دادهای است که با مدل رابطه ای مطابقت داشته باشد و به صورت مجموعه ای از جدول هائی که از دید کاربر قابل درک هستند دیده میشود.
یک سیستم مدیریت پایگاه داده رابطه ای (RDBMS) سیستمی است که داده را طبق مدل رابطه ای مدیریت میکند.
RDBMSها معمولترین نوع سیستمهای مدیریتی پایگاه داده امروزی هستند (نظیر Microsoft SQL Server, Microsoft Access, Oracle, MySQL, PostgreSQL, Sybase, DB2 و Informix).
اکثر RDBMSها SQL را به عنوان زبان پرس و جوی خود بکار میبرند.
- متداولترین مدل است
- بر اساس تئوری ریاضی است
- دادهها و ارتباطات بین آنها در پایگاه داده به صورت مجموعه ای از جداول دیده میشود
- هیچ جدولی دارای سطرهای تکراری نیست
- ترتیب سطرها و ستونها در هر جدول مهم نیست
- ستونها اتمیک هستند یعنی مقادیر ستونها غیرقابل تجزیهاند
- هر مقدار که در دو رکورد مختلف واقع میشود رابطه ای را بین دو آن رکورد میفهماند
- ارتباط رابطهها با یکدیگر از طریق صفات خاصه مشترک انجام میگیرد
- ایجاد، دسترسی و توسعه آن آسان است. بعد از ایجاد پایگاه داده اولیه، جداول جدید میتوانند اضافه شوند بدون اینکه نیاز به تغییر کاربردهای موجود باشد
- مدل دید کاربر است نه روشی که داده بهطور داخلی سازماندهی میشود
پایگاه دادههای چند بعدی
[ویرایش]پایگاه دادههای رابطهای توانست به سرعت بازار را تسخیر کند، هرچند کارهایی نیز وجود داشت که این پایگاه دادهها نمیتوانست به خوبی انجام دهد. به ویژه بهکارگیری کلیدها در چند رکورد مرتبط به هم و در چند پایگاه داده مشترک، کندی سیستم را موجب میشد. برای نمونه برای یافتن نشانی کاربری با نام دیوید، سیستم رابطهای باید نام وی را در جدول کاربر جستجو کند و کلید اصلی را بیابد و سپس در جدول نشانیها، دنبال آن کلید بگردد. اگر چه این وضعیت از نظر کاربر، فقط یک عملیات محسوب، اما به جستجو درجداول نیازمند است که این کار پیچیده و زمان برخواهد بود. راه کار این مشکل این است که پایگاه دادهها اطلاعات صریح دربارهٔ ارتباط بین دادهها را ذخیره نماید. میتوان به جای یافتن نشانی دیوید با جستجو ی کلید در جدول نشانی، اشارهگر به دادهها را ذخیره نمود. در واقع، اگر رکورد اصلی، مالک داده باشد، در همان مکان فیزیکی ذخیره خواهد شد و از سوی دیگر سرعت دسترسی افزایش خواهد یافت. چنین سیستمی را پایگاه دادههای چند بعدی مینامند. این سیستم در هنگامی که از مجموعه دادههای بزرگ استفاده میشود، بسیار سودمند خواهد بود. از آنجاییکه این سیستم برای مجموعه دادههای بزرگ به کار میرود، هیچگاه در بازار بهطور مستقیم عمومیت نخواهد یافت.
پایگاه دادههای شی گرا
[ویرایش]اگر چه سیستمهای چند بعدی نتوانستند بازار را تسخیر نمایند، اما به توسعه سیستمهای شی گرا منجر شدند. این سیستمها که مبتنی بر ساختار و مفاهیم سیستمهای چند بعدی هستند، به کاربر امکان میدهند تا اشیاء را بهطور مستقیم در پایگاه دادهها ذخیره نماید. بدین ترتیب ساختار برنامهنویسی شیء گرا (object oriented) را میتوان بهطور مستقیم و بدون تبدیل نمودن به سایر فرمتها، در پایگاه دادهها مورد استفاده قرار داد. این وضعیت به دلیل مفاهیم مالکیت در سیستم چند بعدی، رخ میدهد. در برنامه شی گرا، یک شی خاص "مالک " سایر اشیا در حافظه است، مثلاً دیوید مالک نشانی خود میباشد. در صورتی که مفهوم مالکیت در پایگاه دادههای رابطهای وجود ندارد.
پایگاهِ دادههایِ سندگرا
[ویرایش]این مدل اجازه میدهد که دادههای برنامه بیشتر به شکل طبیعیشان نزدیک باشد به این خاطر که دادهها میتوانند در سلسله مراتبی پیچیده و تودرتو قرار بگیرند اما قابلیت اجرای درخواست و شمارهبندیشان را از دست ندهند.
منابع
[ویرایش]- دانشنامه آزاد ویکیپدیا به زبان انگلیسی
- سایت تخصصی پایگاه داده ایران SQLIran.com